
上一篇,我们用DTW解决两条曲线相似度的算法,但是这个算法有一个明显的BUG,就是:
DTW和欧式距离对轨迹的个别点差异性非常敏感,如果两个时间序列在大多数时间段具有相似的形态,仅仅在很短的时间具有一定的差异,(即很小的差异也会对相似度衡量产生影响)欧式距离和DTW无法准确衡量这两个时间序列的相似度。LCSS能处理这种问题
为了解决这个问题,我找到了专注用于轨迹相似度的算法LCSS:
0、LCSS基本介绍以及相关内容
- 分析移动用户位置的相似性,提取移动用户的相似路径在出行路径预测、兴趣区域发现、轨迹聚类、个性化路径推荐等领域具有广泛的应用。
- 重点:利用移动用户定位数据找到合适轨迹的表示方法,如何高效计算移动用户轨迹间的相似性成为热点。
本文---基于改进LCSS的移动用户轨迹相似性查询算法研究:
(1)移动用户原始轨迹数据->抽取位置序列->映射为具有时间和地理位置信息的序列。
解决移动用户轨迹数据的稀疏性导致相似度算法效率低下的问题。
(2)FP-tree频繁模式树的加权频繁模式挖掘移动用户轨迹的频繁序列。
解决由于用户轨迹随机性和繁杂性而导致的算法效率低下的问题。
(3)通过改进LCSS算法
结合时间和地理因素衡量用户轨迹的相似性。
- 衡量相似度的方法有很多:欧式距离,动态时间规划DTW,编辑距离EDR,最长公共子序列,最大时间出现法MCT,余弦相似性,Hausdorff距离。其中基于轨迹数据衡量相似度的算法有三种:欧式距离,DTW算法,LCSS算法。
1、欧式距离(关键输入:时间,位置,用户)
- 欧氏距离是指通过计算每个时间点上轨迹所对应的两个点的欧式距离,然后再对所有点的欧式距离进行综合处理,包括取平均值、求和、取中位数等。

其中(,)dist(pkA,pkB)表示用户A和B在某时间段内的距离,,pkA,pkB表示A和B在k时刻的位置,,−,pk,xA−pk,xB表示用户A和用户B在x维度的位置,同理,,−,pk,yA−pk,yB表示用户A和B在y维度上的位置。因此欧式距离为:
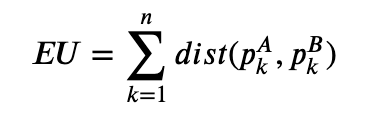
- 欧式距离的缺点:容易受到噪音的影响,尤其是现实中两个移动用户的轨迹在时间和个数上都存在很大差异(缺失,异常),因此需要提前对移动用户的轨迹进行预处理才能使用欧氏距离。
2、动态时间规划DTW算法(关键输入:两个时间序列,包含时间、位置)
- 动态时间规划采用重复点之前的记录点填补对应空缺的方式,以求出的最小距离最为轨迹的相似度量,解决了欧式距离对采样过于苛刻的要求。假设有两个轨迹空间域的离散采样
P=<p_{1}, p_{2}, ..., p_{m}>和Q=<q_{1}, q_{2}, ..., q_{m}>,基于DTW对两条轨迹的采样点数量没有任何的要求,那么两条轨迹之间每两个点的相似度公式为:
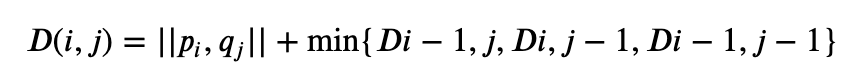
其中||.||||.||为两点坐标的二范数,也就是两点之间的欧式距离。(,)D(i,j)一般也采用欧氏距离,或者其他路径函数也行。因此两条轨迹之间的相似度为:
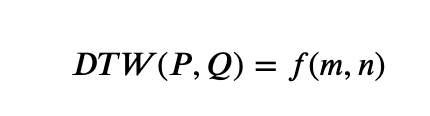
3、最长公共子序列LCSS(两个时间序列,包含:时间,位置)
- 来源:DTW和欧式距离对轨迹的个别点差异性非常敏感,如果两个时间序列在大多数时间段具有相似的形态,仅仅在很短的时间具有一定的差异,(即很小的差异也会对相似度衡量产生影响)欧式距离和DTW无法准确衡量这两个时间序列的相似度。LCSS能处理这种问题。
- 原理:假设现在有两个长度分别为n何m的时间序列数据A和B,那么最长公共子序列的长度为:
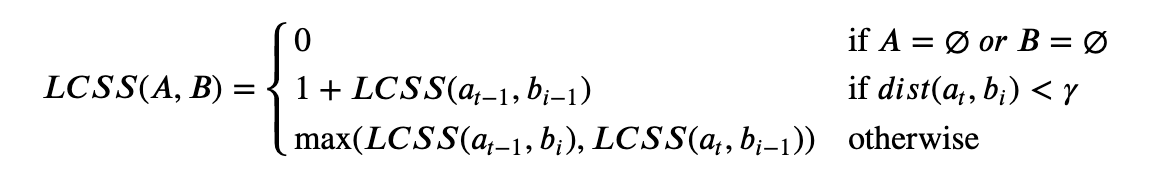
其中,γ为一个成员相似阈值,=1,2,...,t=1,2,...,n;=1,2,...,i=1,2,...,m。基于上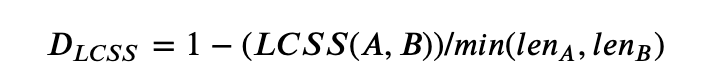
- LCSS算法可以计算两个子序列之间的最长公共子序列。(子序列是有序的,但不一定是连续的,作用对象是序列)
- 例如:序列X= <B,C,D,B>是序列Y = <A,B,C,B,D,A,B>的子序列,对应的下标序列为<2,3,5,7>。
- 匹配:
L(<AGGTAB>, <GXTXAYB>) = 1 + L(<AGGTA>, <GXTXAY>) - 不匹配:
L(<ABCDGH>, <AEDFHR>) = MAX ( L(<ABCDG>, <AEDFHR>), L(<ABCDGH>, <AEDFH>) )
- 匹配:
4、改进的LCSS算法(关键输入:两个时间序列,包含时间、位置)
- 改进LCSS的三个步骤:
- 抽取位置序列:将位置序列映射为具有时间和地理位置信息的序列,以发生时间的序列表示移动用户的轨迹。
- 采用FP-Growth算法挖掘移动用户轨迹的频繁序列。
- 结合时间和地理因素,采用改进LCSS方法衡量用户轨迹的相似性。
4.1 抽取位置序列
- 移动用户时间序列为:
其中(,)(Li,ti)表示用户出现在某个基站的位置Li对应的时间ti。
- 移动用户轨迹为:
其中序列(1,2,1,2)(L1,L2,t1,t2)表示移动用户在时刻1t1出现在基站1L1,然后在时刻2t2离开基站1L1前往基站2L2。
4.2 采用FP-Growth算法挖掘移动用户轨迹的频繁序列
- 移动轨迹的数据的频繁模式定义:→Li→Lj
- 移动用户频繁轨迹提取是从移动用户移动轨迹数据集中提取支持度大于最小支持度阈值的集合。移动用户频繁模式反映了移动用户群体在移动行为上具有相同特征或是规律。
- 通过引入闭合频繁项集保证了移动用户行为信息量最全面且数据规模最小。具体过程如下:
- 首先,以基站平均逗留时间作为项目权重,以各项目count值降序依次为头结点和其他节点,生成条件模式基;
- 然后,采用条件模式基构造对应的加权条件FP树;
- 最后按照设定加权支持度的阈值判断相应的频繁模式。
4.3 基于改进LCSS的移动用户轨迹相似性查询算法
- TP树获得用户常驻区域模式后,以时间系数来反映所有用户在邻近时间相同地理位置的比例。时间相似性系数公式为:
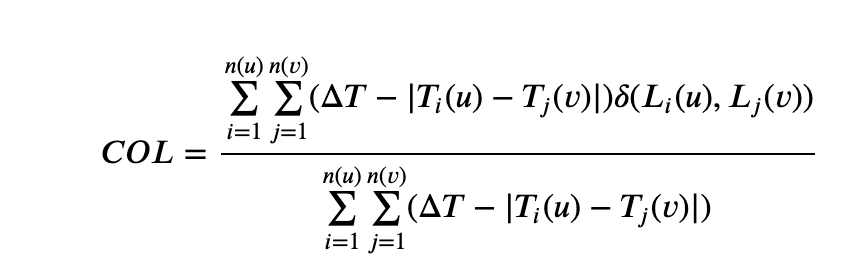
其中,<span class="hljs-variable">$\</span>Delta T<span class="hljs-variable">$为</span>精度(一般设为<span class="hljs-number">1</span>个小时),<span class="hljs-variable">$T_</span>{i}(u)<span class="hljs-variable">$表</span>示移动用户u在某一个时间精度内到达某一个基站<span class="hljs-variable">$L_</span>{i}(u)<span class="hljs-variable">$的</span>时刻,<span class="hljs-variable">$T_</span>{j}(v)<span class="hljs-variable">$表</span>示移动用户v在某一个时间精度内到达某一个基站<span class="hljs-variable">$L_</span>{j}(v)<span class="hljs-variable">$的</span>时刻,<span class="hljs-variable">$\</span>delta (L_{i}(u), L_{j}(v))<span class="hljs-variable">$是</span>一个重合性公式,当两个用户的基站重合时,值为<span class="hljs-number">1</span>,否则为<span class="hljs-number">0</span>。
- 用户重合度:指一个网站内的多少访问者同时浏览器了其他网站。即同时访问两个网站的用户中有多大比例是重合的。假设A和B分别为需要计算用户重合度的<span class="hljs-number">2</span>个网站的独立用户数,则重合度计算公式为:
- 结合时间因素,改进的LCSS相似度算法为:
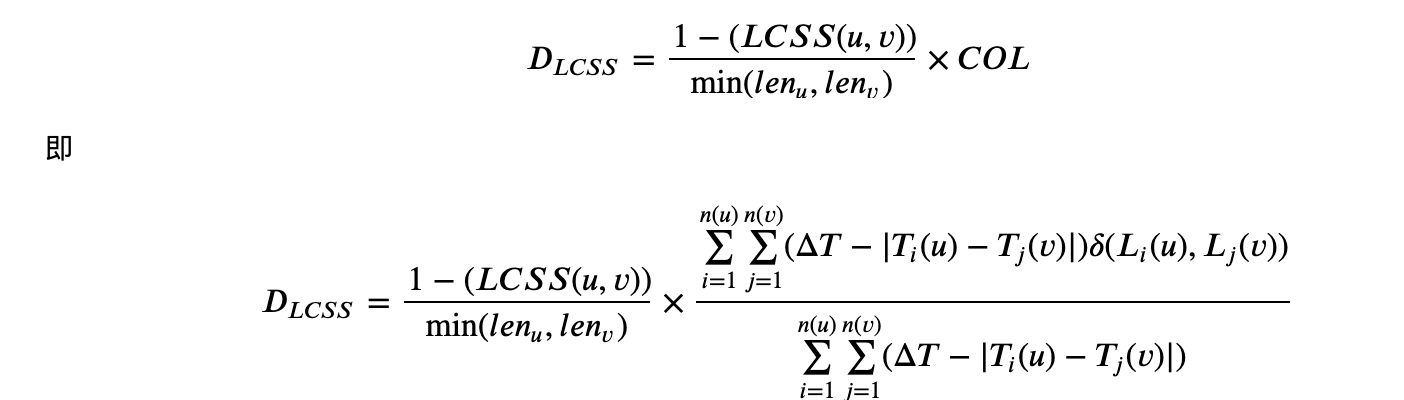
其中,公式的第一部分表示用户u和用户v一天的最长公共子序列,第二部分表示在每一个时间精度下,两位用户在邻近时间相同的地理位置的比例。
4.4 改进LCSS算法与LCSS算法的优缺点
- 优点:结合了时间和地理因素,衡量用户轨迹的相似性,因此提高了相似度计算的准确性。
- 缺点:改进之后,需要抽取时间序列、构造用户轨迹的频繁序列,然后才能用改进的LCSS相似度算法计算用户轨迹的相似度,因此算法模型过程相对比较复杂。
参考:
1、LCSS论文:http://www.cs.bu.edu/groups/dblab/pub_pdfs/icde02.pdf
2、基于改进LCSS的移动用户轨迹相似性查询算法研究:https://www.sohu.com/a/133750116_354885
3、简书:LCSS实现:https://www.jianshu.com/p/d7b8db280a01
4、博客之用户重合度:https://blog.csdn.net/zyy160alex5/article/details/8791864
============ 欢迎各位老板打赏~ ===========


与本文相关的文章
- · python版DTW动态时间规划算法
- · C#字符串相似度算法
- · 在腾讯云函数中使用python打SFTP问题
- · authentic如何把roles返回给sso客户端
- · Docker 快速部署 FastAPI 项目
- · unity3d mysql error: The given key was not present in the dictionary.
- · python 四元数 转 欧拉角
- · macOS Charles 4.x版本的安装及使用(含破解激活)
- · centos安装chrome+chromedriver
- · PyQt5 demo
- · unity3d异步加载场景
- · Unity中将3D模型显示在UI上或者显示在UI前面