
基本开发环境
下载对应包
maven:https://mvnrepository.com/search?q=spark
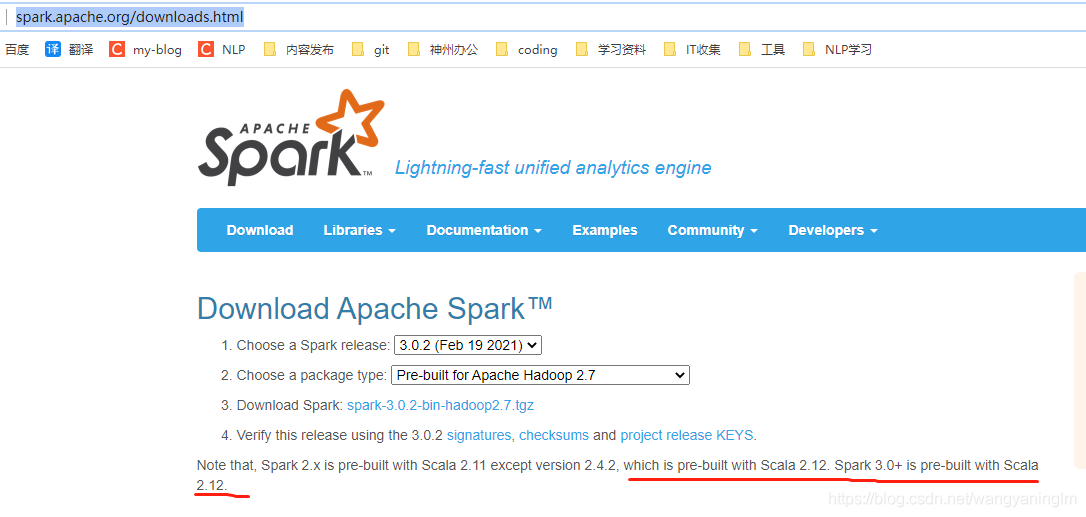
spark:http://spark.apache.org/downloads.html
scala:https://www.scala-lang.org/download/2.12.12.html
注意 spark 3 使用的版本是 scala 2.12.*
java:https://www.oracle.com/java/technologies/javase/javase-jdk8-downloads.html
编译器配置
下载scala 插件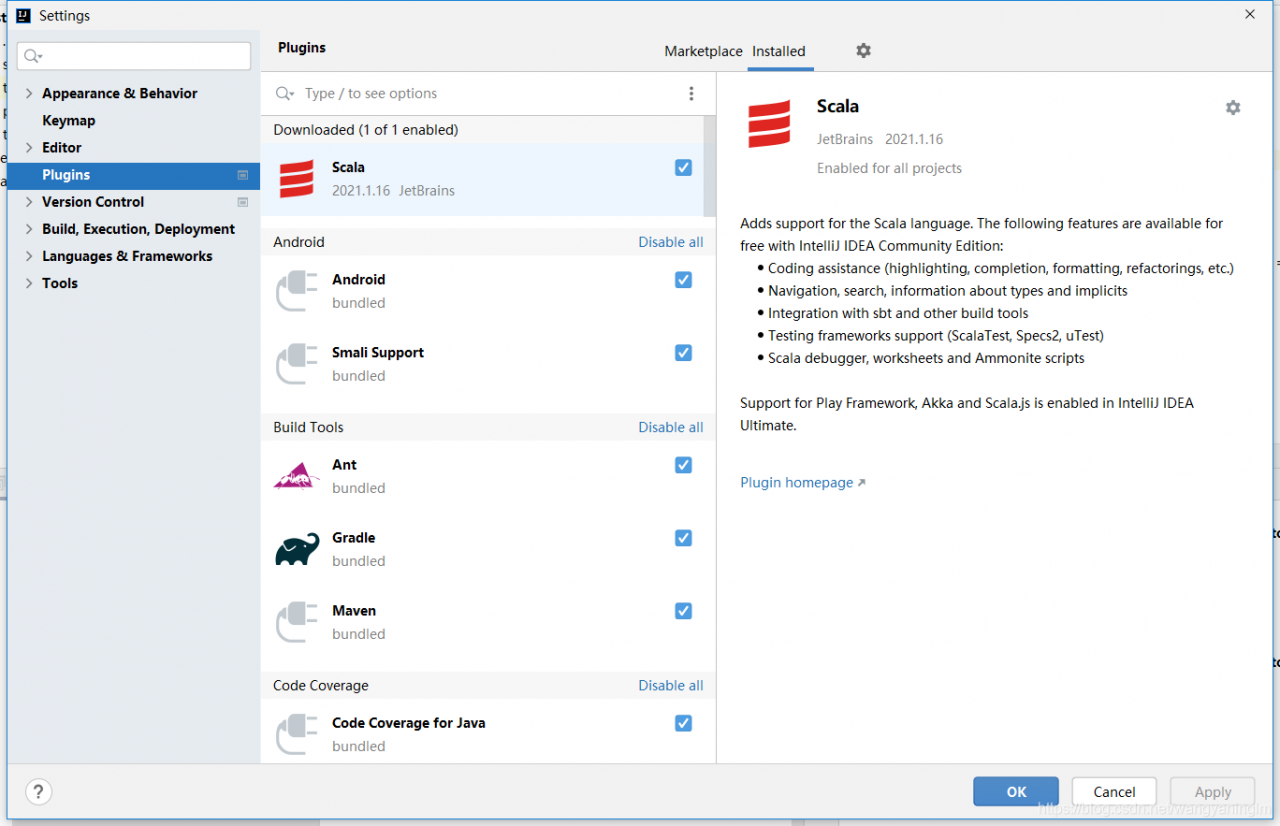
工程构建
配置scala 插件
构建scala 本地jar 包工程
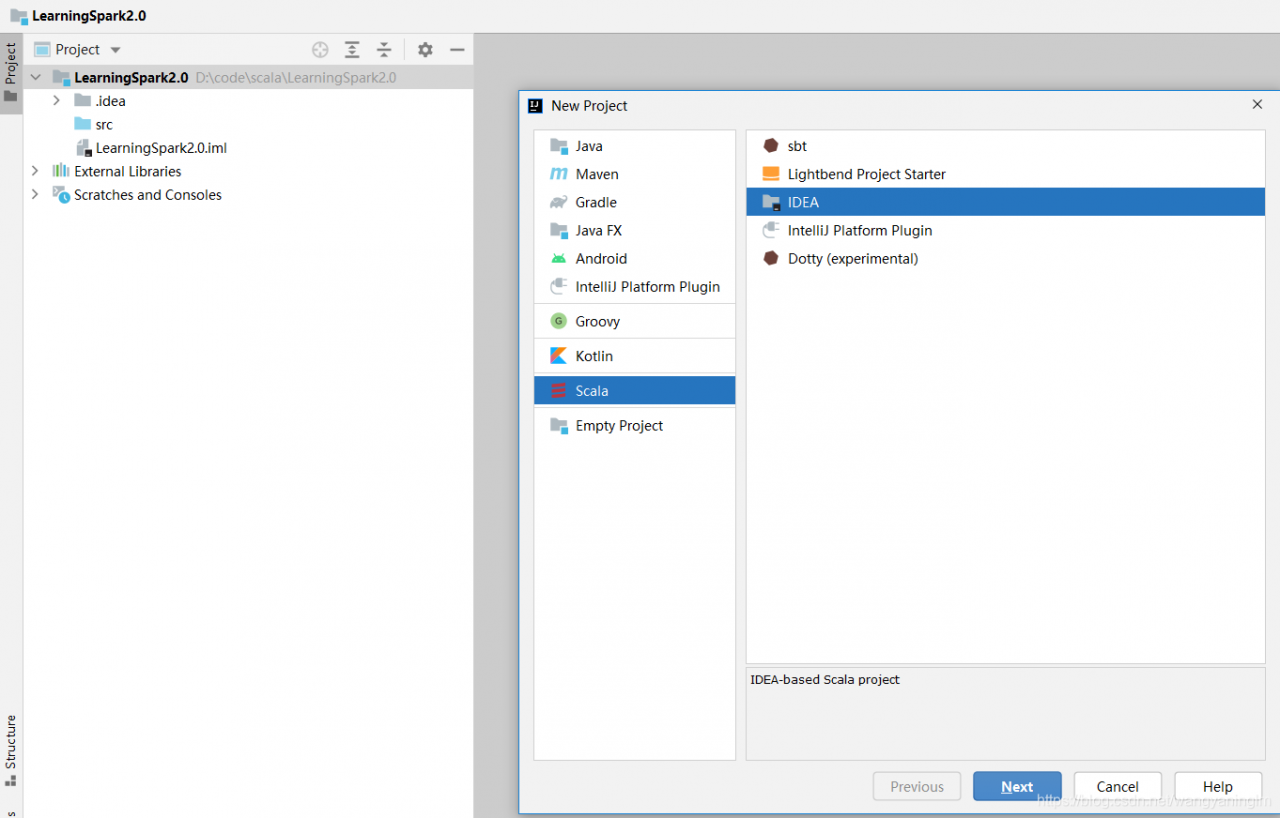
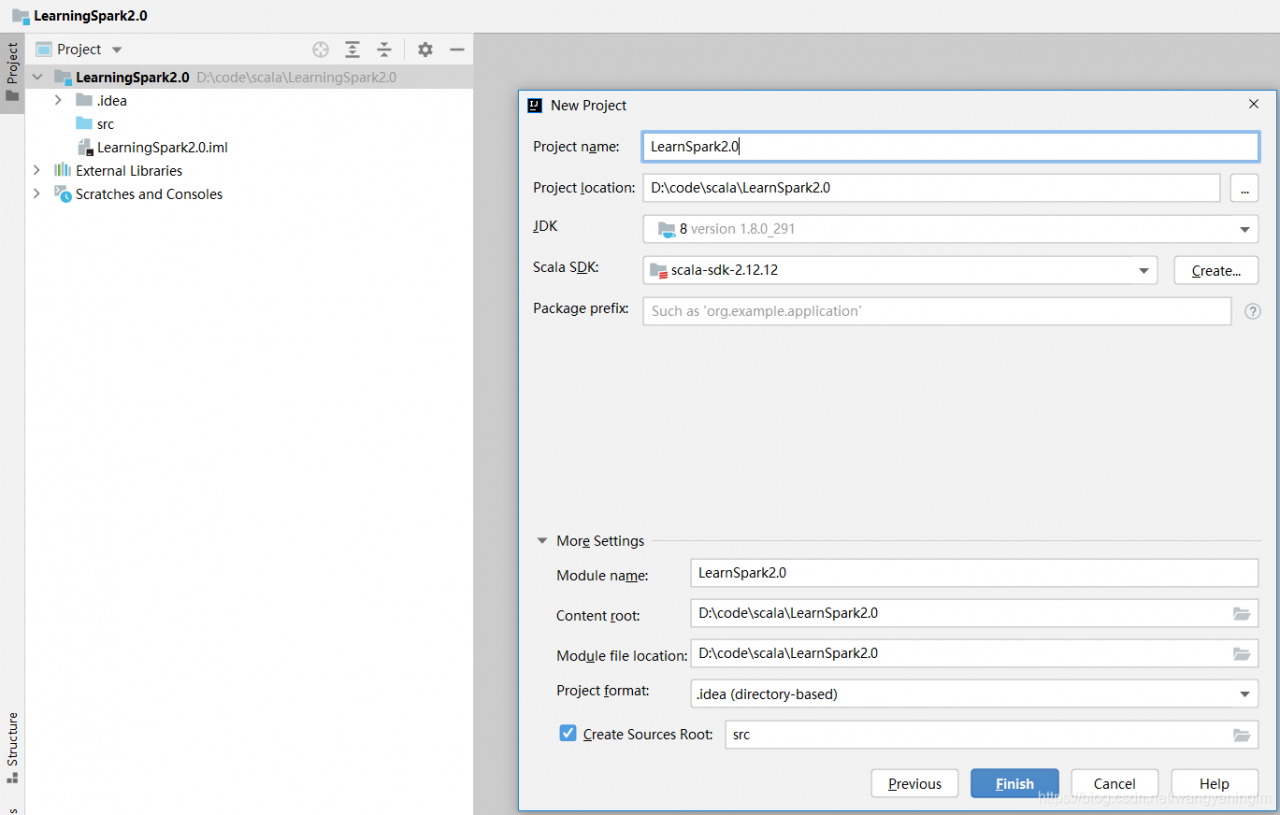
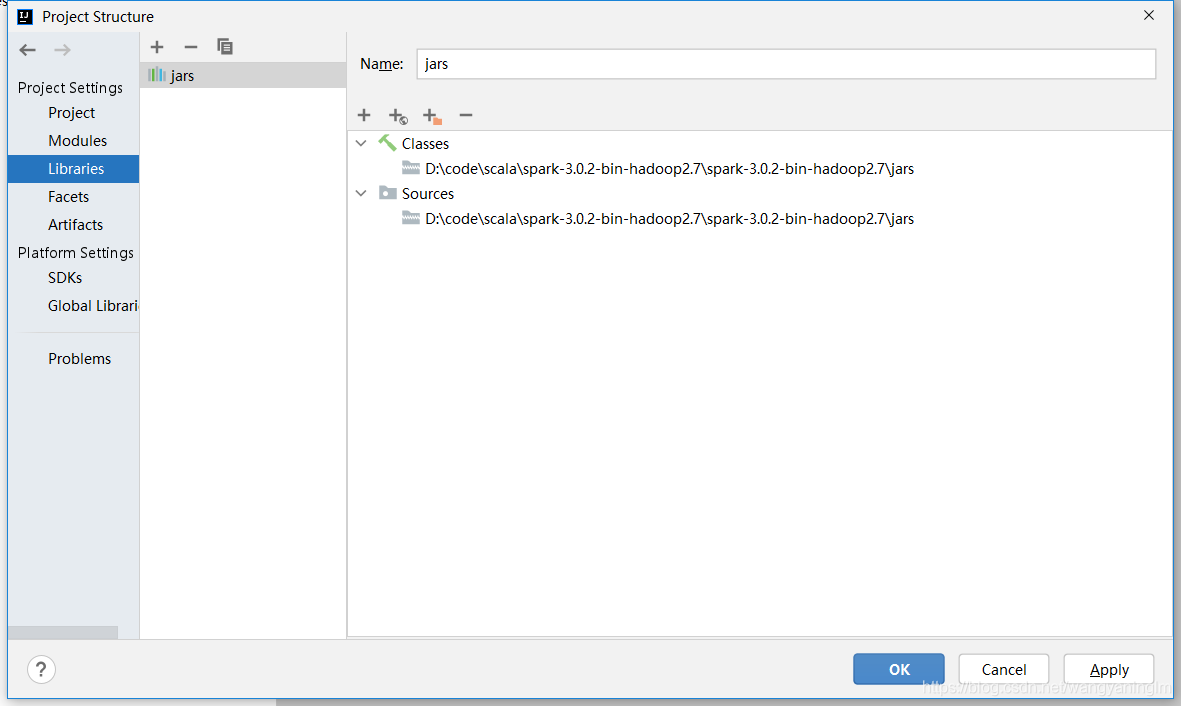
file -》 project structure -》 添加下载的spark 中的jar 包
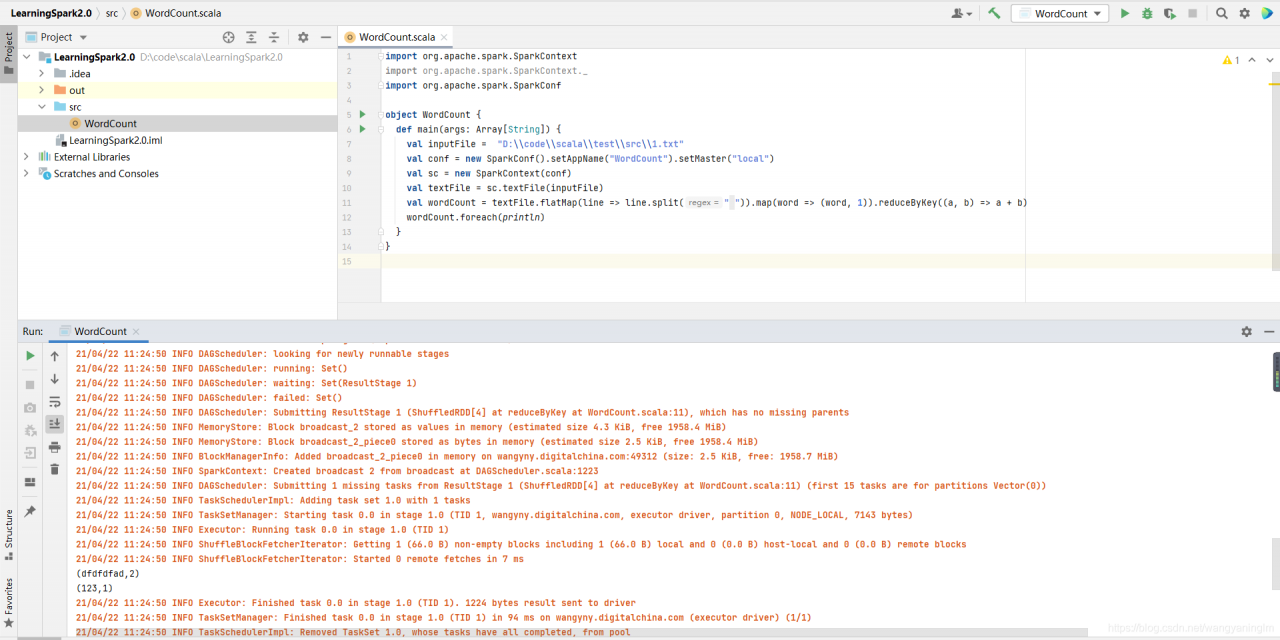
代码:
- import org.apache.spark.SparkContext
- import org.apache.spark.SparkContext._
- import org.apache.spark.SparkConf
- object WordCount {
- def main(args: Array[String]) {
- val inputFile = "D:\\code\\scala\\test\\src\\1.txt"
- val conf = new SparkConf().setAppName("WordCount").setMaster("local")
- val sc = new SparkContext(conf)
- val textFile = sc.textFile(inputFile)
- val wordCount = textFile.flatMap(line => line.split(" ")).map(word => (word, 1)).reduceByKey((a, b) => a + b)
- wordCount.foreach(println)
- }
- }
随便写个text,代码加上路径,点击运行,成功
构建本地maven scala 工程
根据原型模版构建
根据原型模版进行构建
在IDEA启动后进入的界面中,可以看到界面左侧的项目界面,已经有一个名称为simpleSpark的工程。请在该工程名称上右键单击,在弹出的菜单中,选择Add Framework Surport ,在左侧有一排可勾选项,找到scala,勾选即可
在项目文件夹下,右键 建立 路径 src -》 main
然后 Mark Directory as Source Root
不根据原型模版构建
也就是说,我们创建maven 项目的时候不勾选 create from archetype
maven 仓库 下载加速
加速 maven 工程下载,添加阿里的源
setting.xml
<?xml version="1.0" encoding="UTF-8"?>
<settings xmlns="http://maven.apache.org/SETTINGS/1.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/SETTINGS/1.0.0 http://maven.apache.org/xsd/settings-1.0.0.xsd">
<mirrors>
<!-- mirror
| Specifies a repository mirror site to use instead of a given repository. The repository that
| this mirror serves has an ID that matches the mirrorOf element of this mirror. IDs are used
| for inheritance and direct lookup purposes, and must be unique across the set of mirrors.
|
<mirror>
<id>mirrorId</id>
<mirrorOf>repositoryId</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://my.repository.com/repo/path</url>
</mirror>
-->
<mirror>
<id>alimaven</id>
<name>aliyun maven</name>
<url>http://maven.aliyun.com/nexus/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>uk</id>
<mirrorOf>central</mirrorOf>
<name>Human Readable Name for this Mirror.</name>
<url>http://uk.maven.org/maven2/</url>
</mirror>
<mirror>
<id>CN</id>
<name>OSChina Central</name>
<url>http://maven.oschina.net/content/groups/public/</url>
<mirrorOf>central</mirrorOf>
</mirror>
<mirror>
<id>nexus</id>
<name>internal nexus repository</name>
<!-- <url>http://192.168.1.100:8081/nexus/content/groups/public/</url>-->
<url>http://repo.maven.apache.org/maven2</url>
<mirrorOf>central</mirrorOf>
</mirror>
</mirrors>
</settings>
编写pom.xml
结论
国内 开发圈子被阿里 这种用java 的带偏了,总感觉缺了jvm 大项目就做不了了, 看看搭建一个本地开发 idea 的 scala工程废了多少事情?
真是扯犊子,还不如用python,有搭环境这时间 python 系统都开发完了。。。
参考文献
在Windows平台下搭建Spark开发环境(Intellij IDEA):
https://blog.csdn.net/haijiege/article/details/80775792
Spark中IDEA Maven工程创建与配置
https://blog.csdn.net/weixin_45366499/article/details/108518504
hadoop 配置相关问题:
https://www.cnblogs.com/yifeiyu/p/11043005.html
https://www.cnblogs.com/zling/p/10842638.html
————————————————
版权声明:本文为CSDN博主「shiter」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/wangyaninglm/article/details/116004739
============ 欢迎各位老板打赏~ ===========

