
本文开篇,附 Hive 相关内容地址:
Hive官网:http://hive.apache.org
Hive官方参考文档:https://cwiki.apache.org/confluence/display/Hive/GettingStarted
Hive各版本下载地址:http://archive.apache.org/dist/hive
Hive GitHub地址:https://github.com/apache/hive
1.前提
hive 安装之前,需要以 Hadoop 集群为前提,Hive 是执行在 Hadoop集群上的。Hadoop集群安装,参考:
CentOS 7.7 安装 Hadoop 2.10.1集群
CentOS 7.7 安装 Hadoop 3.1.3集群
Hadoop HA版集群安装(待补充)
已安装好的 MySQL数据库,可参考:CentOS 6.2 安装 MySQL 5.7.28
Hadoop集群部署配置信息如下:
2.Hive安装
Ⅰ.下载tar.gz包
下载:apache-hive-3.1.2-bin.tar.gz ,本文 Hive 安装至 /opt/module/目录下。将下载好的 hive.tar.gz 上传至 Linux 服务器,使用命令 tar -zxvf apache-hive-3.1.2-bin.tar.gz -C /opt/module/ 解压缩至指定目录下。同时重命名为 hive-3.1.2。
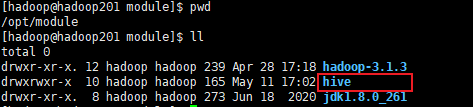
Ⅱ.环境变量配置
备注:my_env.sh 是我们自定义的一个文件,在该文件中可编辑我们自己需要的环境变量,这样可与系统默认的环境变量区分开,也方便编写。环境变量的配置方式有如下几种方式,参考:Linux设置全局变量
修改/etc/profile.d/my_env.sh,添加环境变量,如图所示【本机已配置好jdk、Hadoop】
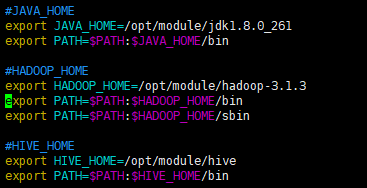
<span class="token comment">#HIVE_HOME</span>
export HIVE_HOME=<span class="token operator">/</span>opt<span class="token operator">/</span>module<span class="token operator">/</span>hive
export PATH=<span class="token variable">$PATH</span>:<span class="token variable">$HIVE_HOME</span><span class="token operator">/</span>bin1
Ⅲ.初始化元数据库
Hive中元数据,默认存储在 Derby 中。使用如下命令,初始化 Derby 元数据。(由于Derby数据库的缺陷,本文选择 MySQL进行元数据存储,本步可省略)
bin/schematool -dbType derby -initSchema
1
由于Derby数据库存在如下2个缺点,所以,需要将 Derby 换成 MySQL 来存储元数据
Derby中的数据没有可视化界面,不方便数据的查看
Derby 默认是单用户模式,只支持一个用户使用 。
初始化元数据库后,便可以通过 bin/hive 命令方式登录。此处选择 MySQL 作为 Hive元数据库,继续向下看
Ⅳ.Hive 元数据配置到 MySQL
1.准备MySQL的JDBC驱动
下载对应版本 MySQL的 JDBC 驱动包,本文使用 MySQL版本为:5.7.28,使用 mysql-connector-java-5.1.37.jar 驱动包,下载地址:https://mvnrepository.com/artifact/mysql/mysql-connector-java/5.1.37

2.将驱动拷贝到 Hive 的 lib 目录下
cp /xxx/mysql-connector-java5.1.37.jar $HIVE_HOME/lib

3.配置 Metastore 到 MySQL
Hive 的 conf 目录下都是相关配置文件。Hive 中的配置文件是 hive-default.xml,这个文件中包含hive所有的默认配置,里面的配置贼多,不方便查看。
我们可以在 conf 目录下,vim 方式自定义一个 hive-site.xml文件,Hive在启动时会动态的去加载 hive-site.xml 中自定义的配置信息,该文件就是用户自定义的一个配置文件,类似于 hdfs-site.xml 。
- <?xml version="1.0"?>
- <?xml-stylesheet type="text/xsl" href="configuration.xsl"?>
- <configuration>
- <!-- jdbc 连接的 URL -->
- <property>
- <name>javax.jdo.option.ConnectionURL</name>
- <value>jdbc:mysql://hadoop201:3306/metastore?useSSL=false</value>
- </property>
- <!-- jdbc 连接的 Driver-->
- <property>
- <name>javax.jdo.option.ConnectionDriverName</name>
- <value>com.mysql.jdbc.Driver</value>
- </property>
- <!-- jdbc 连接的 username(MySQL用户名)-->
- <property>
- <name>javax.jdo.option.ConnectionUserName</name>
- <value>root</value>
- </property>
- <!-- jdbc 连接的 password(MySQL密码) -->
- <property>
- <name>javax.jdo.option.ConnectionPassword</name>
- <value>111111</value>
- </property>
- <!-- Hive 元数据存储版本的验证(Hive元数据默认是存储在Derby中,正常开启时它会去校验Derby,现在要使用MySQL存储元数据,
- 就需要把这个关闭即可,如果开启,MySQL和Derby会导致Hive启动不起来的) -->
- <property>
- <name>hive.metastore.schema.verification</name>
- <value>false</value>
- </property>
- <!--元数据存储授权-->
- <property>
- <name>hive.metastore.event.db.notification.api.auth</name>
- <value>false</value>
- </property>
- <!-- Hive 默认在 HDFS 的工作目录(可以不配置,因为默认就是/user/hive/warehouse,如果不使用默认的位置,可以手动修改) -->
- <property>
- <name>hive.metastore.warehouse.dir</name>
- <value>/user/hive/warehouse</value>
- </property>
- </configuration>
4.在MySQL中创建 metastore数据库
进入数据库,使用命令创建 metastore 数据库
create database metastore;
5.初始化 Hive 元数据库(MySQL)
命令: bin/schematool -initSchema -dbType mysql -verbose (-verbose 是显示详情的意思,可省略)
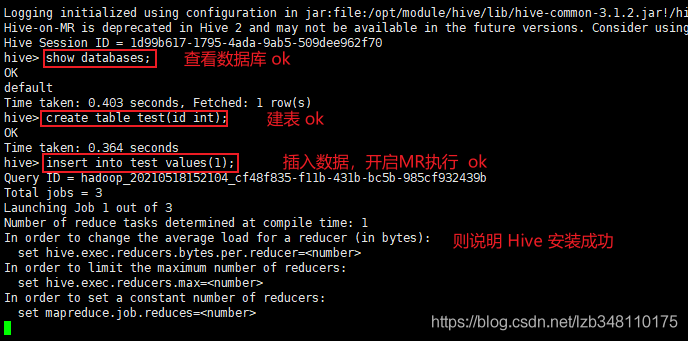
3.启动Hive客户端(命令行方式启动): hive
注意: 因为 Hive 依赖于HDFS、MapReduce、Yarn的。所以需要先启动Hadoop集群
判断 Hive 安装是否成功
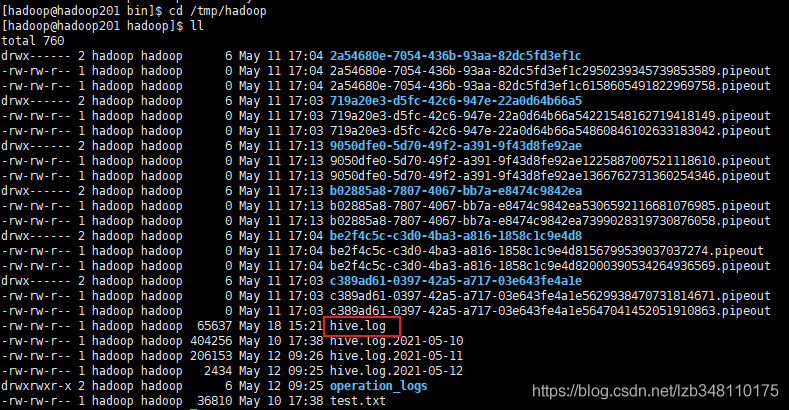
Ⅰ.Hive日志所在目录
如果在配置时,没有修改 hive 日志打印位置,默认是在 /tmp/当前用户名/hive.log 目录下
Hive如何配置日志路径
进入到 hive 的 conf 目录下;
将 hive-log4j2.properties.template 文件名修改为 hive-log4j2.properties
vim 打开文件
修改 property.hive.log.dir = /opt/module/hive/logs (日志文件路径)
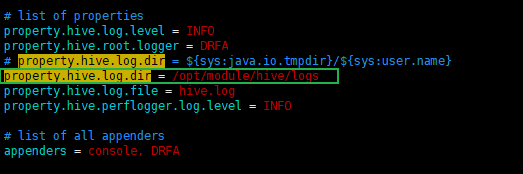
修改后日志所在路径,如下图:
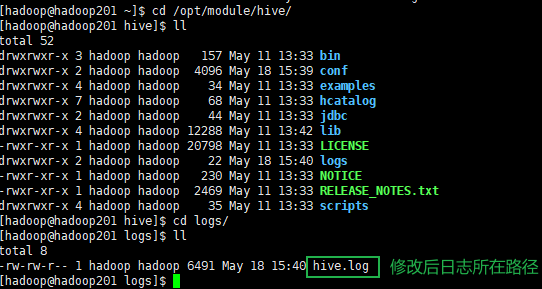
v
Ⅱ.bin 目录命令介绍
1.schematool 初始化元数据 命令
2.hive 在本地启动一个 hive 客户端
3.以下两个是通过JDBC方式来访问Hive使用的
hiveserver2 服务端
beeline 客户端
4.其他方式访问 Hive
通过 bin/hive 命令行方式连接 Hive客户端,这种方式只能在Linux客户端使用 Hive。
如果我们需要在 IDEA、第三方框架中使用 Hive,此时就完全不能够使用。Hive也没有启动任何服务,也没有启任何端口,外部服务第三方框架如果要想去操作 Hive,此时就没法来连接了。(之前要连Hadoop,连接 NameNode 就可以,要连接Yarn,连接 ResourceManager 即可,起码都有一个端口可以去允许连接,这种情况下只能在Linux客户端进行使用,如果要第三方框架用 Hive 进行一些数据处理,不好意思,用不了!!!)
4.1 使用 Metastore 方式访问 Hive
除了 Linux 通过 bin/hive 方式连接到 Hive客户端,第二种连接方式,就是给 Hive 启动一个元数据服务,如果第三方想要使用,将第三方连接到元数据服务,即可连接到 Hive 的服务。(因为元数据中存储着数据输在的位置,映射等内容,只要能够连接到元数据,就能够找到数据所在位置,即可使用 Hive 服务了)具体配置如下:
1.在 hive-site.xml 中添加如下配置,指定元数据服务地址
<!-- 指定存储元数据要连接的地址,默认端口号是9083(元数据存储在MySQL,MySQL在 Hadoop201 【192.168.204.201】节点) -->
- <property>
- <name>hive.metastore.uris</name>
- <value>thrift://hadoop201:9083</value>
- </property>
2.启动 metastore 服务
9083端口配置好后,就可以启动元数据服务,提供9083服务供三方等调用。
启动命令:hive --service metastore
注意:元数据服务是一个前台进程,启动后会将当前窗口占用,导致当前窗口无法进行其他操作,后续可以将元数据服务以后台方式启动,继续向下看。
3.启动 bin/hive 客户端服务
提供了9083端口,此时可以供三方调用元数据服务了。如果配置了9083端口,但是没有启动元数据服务,那么通过 bin/hive 方式连接,前台显示连接hive成功,但是后台日志已经在报错,它会尝试去连接9083端口。配置了9083端口,bin/hive 就必须使用元数据服务的方式去连接,必须开启元数据服务。。
这样有个好处,可能对本地服务启动比较麻烦点,每次都需要启动 metastore 元数据服务,但是对于第三方来说,就可以连接到 hive 的元数据服务了,就可以来使用 Hive了。这样就将 Hive 变成了一个服务,可供外界通过9083端口访问了。
4.2 使用 JDBC 方式访问 Hive(beeline客户端访问)
除使用 Metastore 元数据服务方式访问 Hive 外,在 Hive 中还提供了 JDBC 方式来连接。我们只需要给它一个Driver驱动、username、url 地址,也能连接到 Hive 上。
在 Hive 中关于 JDBC 相关的服务,叫做 hiveserver2,现在使用JDBC方式连接到 Hive,除了 hiveserver2 需要启动,metastore元数据服务也得启动。
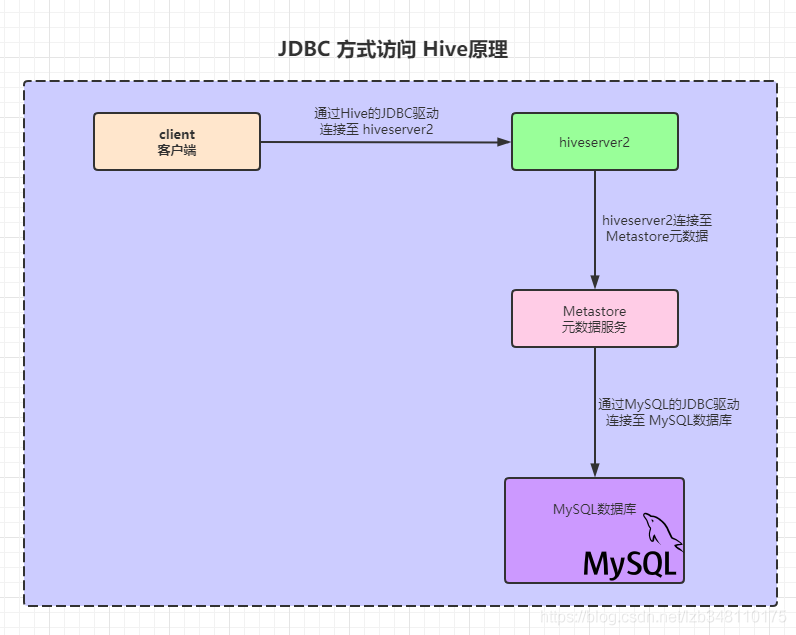
启动一个 hiverserver2 服务,它会去调用 metastore 元数据服务,metastore 提供元数据再通过 JDBC 的方式,连接MySQL,Client 再通过 JDBC 方式,连接到 hiveserver2上。
这个过程一共用到2个JDBC。Client 连接 hiverserver2 使用的是 Hive 的 JDBC 驱动,metastore 通过 JDBC 连接MySQL数据库,使用的是 MySQL 的 JDBC 驱动。这样,客户端就可以通过发送SQL的方式,去一步步执行,有点绕。这块有两个地方需要 JDBC 的访问。
具体配置如下:
- <!-- 指定 hiveserver2 连接的 host -->
- <property>
- <name>hive.server2.thrift.bind.host</name>
- <value>hadoop201</value>
- </property>
- <!-- 指定 hiveserver2 连接的端口号 -->
- <property>
- <name>hive.server2.thrift.port</name>
- <value>10000</value>
- </property>
2.启动 hiveserver2 服务
10000端口配置好后,就可以启动 hiveserver2 服务
启动命令:hive --service hiveserver2

注意:元数据服务是一个前台进程,启动后会将当前窗口占用,导致当前窗口无法进行其他操作,后续可以将元数据服务以后台方式启动,继续向下看。
提示:开启hiveserver2服务,一共有2种方式
①使用本身提供的命令 bin/hiveserver2
在 Hive 2.x 中,MR 引擎已经标记为过时,建议使用Spark、Tez 引擎。使用 bin/hiveserver2 方式启动,它会去校验2次,在日志中间会有2次报错,提示 Tez 相关class类找不到。报错并不会影响hive启动,找不到 Tez 后最终会使用 MR 引擎,只是说 2 次校验,需要等待的时间比较长。
②另一种方式,和启动元数据服务一样,通过命令 hive --service hiveserver2 启动
这种方式启动 hiveserver2 ,会校验1次。相对于校验 2次 来说,等待时间会比较短点。其他没啥任何区别。
5.Hive 服务启动脚本
命令hive --service metastore,启动 Metastore 元数据服务;命令hive --service hiveserver2,用来启动 hiveserver2 服务,但是这两个命令都是前台进程,前台进程会占用当前窗口导致我们无法操作,也没法关闭窗口。此时就需要将前台进程挂载到后台进程去运行。
前台启动的方式导致需要打开多个 shell 窗口,可以使用如下方式后台方式启动:
nohup:放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态
/dev/null:是 Linux 文件系统中的一个文件,被称为黑洞,所有写入改文件的内容都会被自动丢弃
2>&1 :表示将错误重定向到标准输出上(Shell 中 0 是标准输入(键盘输入) 1、2 都是输出 1是标准输出 2是错误输出,标准输出和错误输出,默认都是输出在控制台上)
&:放在命令结尾,表示后台运行
一般会组合使用:nohup [xxx 命令操作]> file 2>&1 &,表示将 xxx 命令运行的结果输出到 file 中,并保持命令启动的进程在后台运行。
后台进程方式运行命令:
metastore服务:nohup hive --service metastore 2>&1 &
hiveserver2服务:nohup hive --service hiveserver2 2>&1 &
通过后台方式运行后,虽然会将当前窗口空出来,但是在需要关闭某个服务时,就不知道哪个端口到底对应哪个服务了。因为 hiveserver2、metastore、bin\hive 启动的进程名都叫做 RunJar,这种方式关闭服务,如果不知道进程ID,就只能猜,还不是太方便。
Ⅰ.编写脚本
为了方便 Hive 服务的启停、使用,可以直接编写脚本来管理服务的启动和关闭。该脚本支持 4个参数,start 启动服务,stop 关闭服务,restart 重启服务,status 查看启动服务状态。脚本内容如下所示:
编写脚本:vim $HIVE_HOME/bin/hiveservices.sh
添加执行权限:chmod +x $HIVE_HOME/bin/hiveservices.sh
启动Hive服务:hiveservices.sh start
脚本内容如下:
- #!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
if [ ! -d $HIVE_LOG_DIR ]
then
mkdir -p $HIVE_LOG_DIR
fi
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac
Ⅱ.脚本方式启动服务(MetaStore + hiveserver2服务)

Ⅲ.打印当前 库 和 表头
在使用 bin/hive 进入 Hive 客户端后,我们只能看到一个 hive>这样一个标签,在进行一系列操作之后,然而1.我们并不知道目前所处在哪个库操作,2.在进行 select 查询时也不显示每一列代表什么字段,这样用起来也有些不是很方便,所以我们可以在 hive-site.xml 中对其进行配置,来显示库名 和 表头信息。
- 在 hive-site.xml 中,加入如下 2 个配置即可:
- <!-- 打印表头-->
- <property>
- <name>hive.cli.print.header</name>
- <value>true</value>
- </property>
- <!-- 打印当前库名-->
- <property>
- <name>hive.cli.print.current.db</name>
- <value>true</value>
- </property>
============ 欢迎各位老板打赏~ ===========

