
作者简介:吉日嘎拉(蒙古语为吉祥如意),2000年毕业于黑龙江大学计算机系软件专业,目前定居杭州,典型的IT软件土鳖一个,外号“软件包工头”。
精心维护通用权限管理系统组件有8年多,3年的不断推广,20万行经典的业务逻辑积累,经过上万次的调试修正,经历了四百个付费客户,上百软件公司的实战开发。
11年以上开发经验,外企工作5年,上市公司3年,独立经营软件公司2年,主持研发部门管理工作4年以上。
将权限管理、工作流管理做到我能力的极致,一个人只能做好那么很少的几件事情。 Mail:jirigala_bao@hotmail.com
——————————————————————————————————————————————————————————————————————
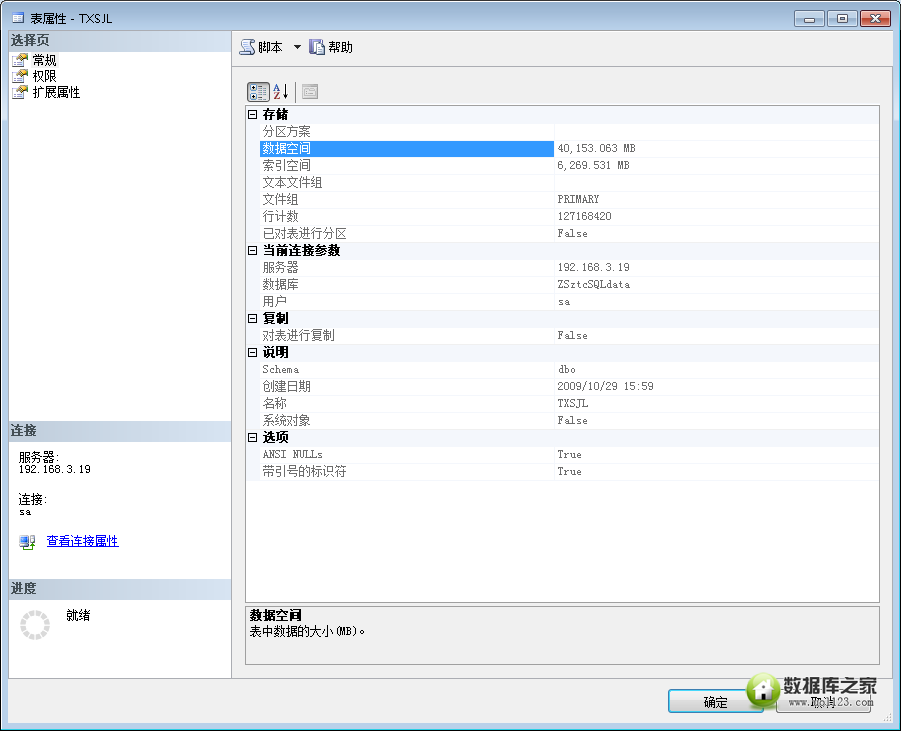
上亿条记录的查询测试、查询优化
SELECT COUNT(1) FROM TXSJL 耗费一分钟多,创建所引耗费 1小时50分钟左右。
这么海量的数据,平生还是第一次折腾,虽然几年前在宁波海关的数据中心也见过上亿条的数据,但是没自己操作过。
为了产生上亿条的数据,折腾了整整1天时间,产生均匀分布的演示数据,每次执行一个SQL语句大该花费20分钟左右同时能产生200万条记录,连续产生了接近5-6次,有了2000万条演示数据,这些整整耗费了一上午。
中午去打台球,为了提高演示数据的速度,把表的索引先干掉否则产生演示数据太慢,干掉索引大概花费了20分钟左右,然后每次1000万条的演示数据插入,每次大概耗费20分钟,中午打好台球回来产生了2批次数据,然后数据库连接超时,下午又批量生成了7-8次,接近到4点左右产生了1亿多条演示数据。
接着发现服务器的硬盘空间要满了,没办法再产生演示数据了,先停止插入演示数据,重新整理数据库空间等,腾出一些地方再继续产生索引,索引创建大概耗时1小时50分钟,下班时已经产生好演示数据及相关的优化索引等,准备就绪。
由于程序先前在1千多万条记录上优化过,到了1亿多条数据后,居然性能下降不明显,运行速度照样还是蛮快的开心啊,同时也佩服数据库的强大,真TMD的是有科技含量啊,1亿多条数据居然运算的还是很快,应该是其中的所引起了很大作用。
我经常形容自己一年死3回,升华3次,今天算其中的一次吧,算是今年真正升华了一次,平生第一次亲手折腾上亿条数据的表,做优化工作;虽然算不上专业的DBA,但非专业的DBA也难超越我了,哈哈。偷偷高兴一下,给自己鼓鼓劲儿。
其实亲身能体验一下上亿条数据,程序运行会怎么样?运算速度会怎么样?会遇到什么问题?要注意哪些环节?还是很有价值的。说得俗一些如何快速产生上亿条测试数据也是一门学问,呵呵,而且要分布均匀的哦。
数据文件占40G左右,所引占6G左右空间。
============ 欢迎各位老板打赏~ ===========

