
部署一个包含Ollama、Qwen 2-7B(一个大型语言模型)以及Open WebUI的系统,通常需要以下步骤:
1. **环境准备**:
- 确保您的服务器或本地计算机满足运行Ollama和Qwen 2-7B模型的硬件要求,包括足够的内存、CPU和GPU资源。
测试需要 7G的内存,显卡要求不高2G足够。
2. **安装依赖**:
无
3. **获取Ollama和Qwen 2-7B模型**:
- 从官方源或可信的第三方源获取Ollama和Qwen 2-7B模型的安装包或代码库。
- 下载ollama,登录Ollama官网下载Ollama安装包
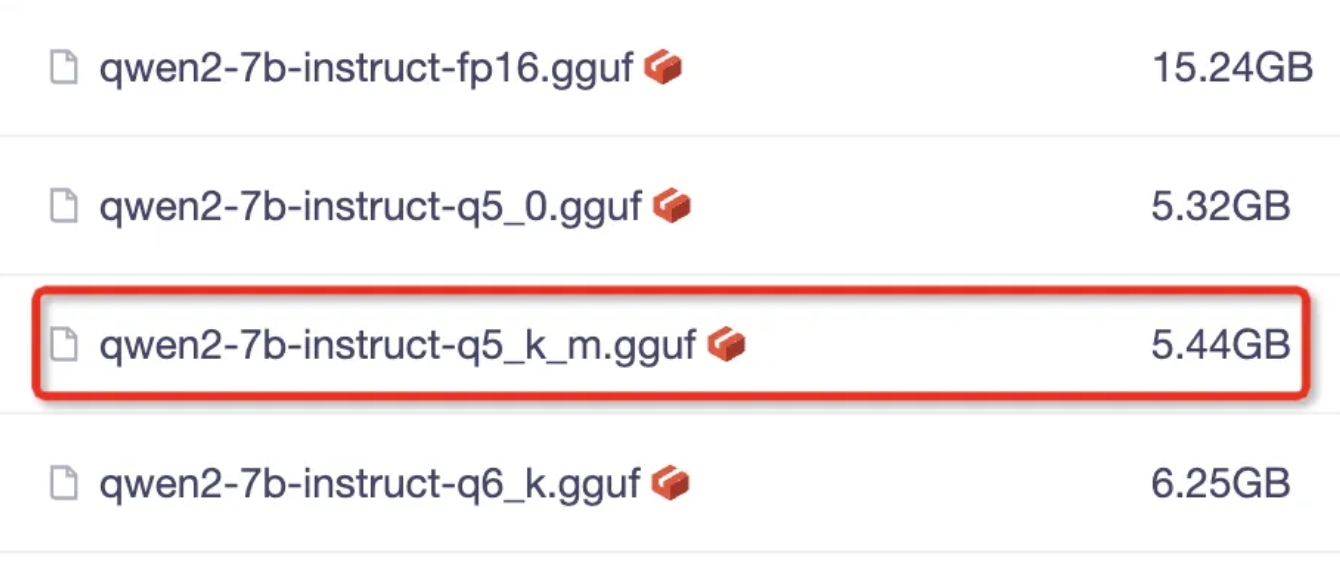
GitHub:https://github.com/ollama/ollama?tab=readme-ov-file - 下载qwen2-7b https://modelscope.cn/models/qwen/Qwen2-7B-Instruct-GGUF/filesQwen2-7B-Instruct-GGUF模型文件列表,我们选择qwen2-7b-instruct-q5_k_m.gguf并下载:
4. **安装转化模型文件为Ollama可用**:
- 在我们存放Qwen2-7B的 GGUF 模型文件目录中,创建一个文件名为Modelfile的文件,该文件的内容如下:
FROM ./qwen2-7b-instruct-q5_k_m.gguf
然后在Terminal终端,使用这个文件创建Ollama模型,这里我把Ollama的模型取名为Qwen2-7B:
ollama create Qwen2-7B -f ./Modelfile
最后,ollama list,可看到转换完成的模型。

5. **配置Ollama**:
- 配置Ollama以使用Qwen 2-7B模型。这可能包括设置环境变量、编辑配置文件等。
一定要设置环境变量(windows 去高级设置中增加系统环境变量):OLLAMA_HOST=192.168.2.106:11434

6. **启动Ollama服务**:
- 使用适当的命令启动Ollama服务,确保它可以访问Qwen 2-7B模型并提供API接口。
ollama serve
7. **安装Open WebUI**:
- 如果Open WebUI是一个独立的前端界面,您可能需要通过Git克隆其代码库或下载发行版,并根据其文档安装和配置。
docker run -d -p 3000:8080 --add-host=192.168.2.106:11434 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui
最后看效果图:

请注意,上述步骤是通用的指导,具体实施可能会根据Ollama、Qwen 2-7B模型和Open WebUI的具体实现和版本有所不同。务必参考每个组件的官方文档来获取详细的安装和配置指南。如果您在部署过程中遇到具体问题,可以根据错误信息进行相应的调试。
============ 欢迎各位老板打赏~ ===========

