
数据库优化包含以下三部分,数据库自身的优化,数据库表优化,程序操作优化.此文为第一部分
数据库性能优化一:数据库自身优化
优化①:增加次数据文件,设置文件自动增长(粗略数据分区)
1.1:增加次数据文件
从SQL SERVER 2005开始,数据库不默认生成NDF数据文件,一般情况下有一个主数据文件(MDF)就够了,但是有些大型的数据库,由于信息很多,而且查询频繁,所以为了提高查询速度,可以把一些表或者一些表中的部分记录分开存储在不同的数据文件里
由于CPU和内存的速度远大于硬盘的读写速度,所以可以把不同的数据文件放在不同的物理硬盘里,这样执行查询的时候,就可以让多个硬盘同时进行查询,以充分利用CPU和内存的性能,提高查询速度。 在这里详细介绍一下其写入的原理,数据文件(MDF、NDF)和日志文件(LDF)的写入方式是不一样的:
数据文件:SQL Server按照同一个文件组里面的所有文件现有空闲空间的大小,按这个比例把新的数据分布到所有有空间的数据文件里,如果有三个数据文件A.MDF,B.NDF,C.NDF,空闲大小分别为200mb,100mb,和50mb,那么写入一个70mb的东西,他就会向ABC三个文件中一次写入40、20、10的数据,如果某个日志文件已满,就不会向其写入
日志文件:日志文件是按照顺序写入的,一个写满,才会写入另外一个
由上可见,如果能增加其数据文件NDF,有利于大数据量的查询速度,但是增加日志文件却没什么用处。
1.2:设置文件自动增长(大数据量,小数据量无需设置)
在SQL Server 2005中,默认MDF文件初始大小为5MB,自增为1MB,不限增长,LDF初始为1MB,增长为10%,限制文件增长到一定的数目,一般设计中,使用SQL自带的设计即可,但是大型数据库设计中,最好亲自去设计其增长和初始大小,如果初始值太小,那么很快数据库就会写满,如果写满,在进行插入会是什么情况呢?当数据文件写满,进行某些操作时,SQL Server会让操作等待,直到文件自动增长结束了,原先的那个操作才能继续进行。如果自增长用了很长时间,原先的操作会等不及就超时取消了(一般默认的阈值是15秒),不但这个操作会回滚,文件自动增长也会被取消。也就是说,这一次文件没有得到任何增大,增长的时间根据自动增长的大小确定的,如果太小,可能一次操作需要连续几次增长才能满足,如果太大,就需要等待很长时间,所以设置自动增长要注意一下几点:
1)要设置成按固定大小增长,而不能按比例。这样就能避免一次增长太多或者太少所带来的不必要的麻烦。建议对比较小的数据库,设置一次增长50 MB到100 MB。对大的数据库,设置一次增长100 MB到200 MB。
2)要定期监测各个数据文件的使用情况,尽量保证每个文件剩余的空间一样大,或者是期望的比例。
3)设置文件最大值,以免SQL Server文件自增长用尽磁盘空间,影响操作系统。
4)发生自增长后,要及时检查新的数据文件空间分配情况。避免SQL Server总是往个别文件写数据。
因此,对于一个比较繁忙的数据库,推荐的设置是开启数据库自动增长选项,以防数据库空间用尽导致应用程序失败,但是要严格避免自动增长的发生。同时,尽量不要使用自动收缩功能。
1.3 数据和日志文件分开存放在不同磁盘上
数据文件和日志文件的操作会产生大量的I/O。在可能的条件下,日志文件应该存放在一个与数据和索引所在的数据文件不同的硬盘上以分散I/O,同时还有利于数据库的灾难恢复。
优化②:表分区,索引分区 (优化①粗略的进行了表分区,优化②为精确数据分区)
为什么要表分区?
当一个表的数据量太大的时候,我们最想做的一件事是什么?将这个表一分为二或者更多分,但是表还是这个表,只是将其内容存储分开,这样读取就快了N倍了
原理:表数据是无法放在文件中的,但是文件组可以放在文件中,表可以放在文件组中,这样就间接实现了表数据存放在不同的文件中。能分区存储的还有:表、索引和大型对象数据 。
SQL SERVER 2005中,引入了表分区的概念, 当表中的数据量不断增大,查询数据的速度就会变慢,应用程序的性能就会下降,这时就应该考虑对表进行分区,当一个表里的数据很多时,可以将其分拆到多个的表里,因为要扫描的数据变得更少 ,查询可以更快地运行,这样操作大大提高了性能,表进行分区后,逻辑上表仍然是一张完整的表,只是将表中的数据在物理上存放到多个表空间(物理文件上),这样查询数据时,不至于每次都扫描整张表
2.1什么时候使用分区表:
1、表的大小超过2GB。
2、表中包含历史数据,新的数据被增加到新的分区中。
2.2表分区的优缺点
表分区有以下优点:
1、改善查询性能:对分区对象的查询可以仅搜索自己关心的分区,提高检索速度。
2、增强可用性:如果表的某个分区出现故障,表在其他分区的数据仍然可用;
3、维护方便:如果表的某个分区出现故障,需要修复数据,只修复该分区即可;
4、均衡I/O:可以把不同的分区映射到磁盘以平衡I/O,改善整个系统性能。
缺点:
分区表相关:已经存在的表没有方法可以直接转化为分区表。不过 Oracle 提供了在线重定义表的功能.
2.3表分区的操作三步走
2.31 创建分区函数
- CREATE PARTITION FUNCTION xx1(int)
- AS RANGE LEFT FOR VALUES (10000, 20000);
注释:创建分区函数:myRangePF2,以INT类型分区,分三个区间,10000以内在A 区,1W-2W在B区,2W以上在C区.
2.3.2创建分区架构
- CREATE PARTITION SCHEME myRangePS2
- AS PARTITION xx1
- TO (a, b, c);
注释:在分区函数XX1上创建分区架构:myRangePS2,分别为A,B,C三个区间
A,B,C分别为三个文件组的名称,而且必须三个NDF隶属于这三个组,文件所属文件组一旦创建就不能修改
2.3.3 对表进行分区
常用数据规范--数据空间类型修改为:分区方案,然后选择分区方案名称和分区列列表,结果如图所示:
也可以用sql语句生成
- CREATE TABLE [dbo].[AvCache](
- [AVNote] [varchar](300) NULL,
- [bb] [int] IDENTITY(1,1)
- ) ON [myRangePS2](bb); --注意这里使用[myRangePS2]架构,根据bb分区
2.3.4查询表分区
SELECT *, $PARTITION.[myRangePF2](bb) FROM dbo.AVCache
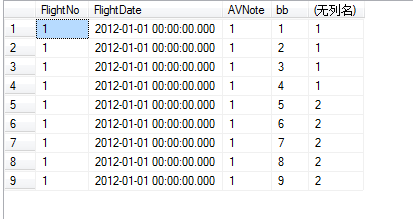
这样就可以清楚的看到表数据是如何分区的了
2.3.5创建索引分区

优化③:分布式数据库设计
分布式数据库系统是在集中式数据库系统的基础上发展起来的,理解起来也很简单,就是将整体的数据库分开,分布到各个地方,就其本质而言,分布式数据库系统分为两种:1.数据在逻辑上是统一的,而在物理上却是分散的,一个分布式数据库在逻辑上是一个统一的整体,在物理上则是分别存储在不同的物理节点上,我们通常说的分布式数据库都是这种2.逻辑是分布的,物理上也是分布的,这种也成联邦式分布数据库,由于组成联邦的各个子数据库系统是相对“自治”的,这种系统可以容纳多种不同用途的、差异较大的数据库,比较适宜于大范围内数据库的集成。
分布式数据库较为复杂,在此不作详细的使用和说明,只是举例说明一下,现在分布式数据库多用于用户分区性较强的系统中,如果一个全国连锁店,一般设计为每个分店都有自己的销售和库存等信息,总部则需要有员工,供应商,分店信息等数据库,这类型的分店数据库可以完全一致,很多系统也可能导致不一致,这样,各个连锁店数据存储在本地,从而提高了影响速度,降低了通信费用,而且数据分布在不同场地,且存有多个副本,即使个别场地发生故障,不致引起整个系统的瘫痪。 但是他也带来很多问题,如:数据一致性问题、数据远程传递的实现、通信开销的降低等,这使得分布式数据库系统的开发变得较为复杂,只是让大家明白其原理,具体的使用方式就不做详细的介绍了。
优化④:整理数据库碎片
如果你的表已经创建好了索引,但性能却仍然不好,那很可能是产生了索引碎片,你需要进行索引碎片整理。
什么是索引碎片?
由于表上有过度地插入、修改和删除操作,索引页被分成多块就形成了索引碎片,如果索引碎片严重,那扫描索引的时间就会变长,甚至导致索引不可用,因此数据检索操作就慢下来了。
如何知道是否发生了索引碎片?
在SQLServer数据库,通过DBCC ShowContig或DBCC ShowContig(表名)检查索引碎片情况,指导我们对其进行定时重建整理。

通过对扫描密度(过低),扫描碎片(过高)的结果分析,判定是否需要索引重建,主要看如下两个:
Scan Density [Best Count:Actual Count]-扫描密度[最佳值:实际值]:DBCC SHOWCONTIG返回最有用的一个百分比。这是扩展盘区的最佳值和实际值的比率。该百分比应该尽可能靠近100%。低了则说明有外部碎片。
Logical Scan Fragmentation-逻辑扫描碎片:无序页的百分比。该百分比应该在0%到10%之间,高了则说明有外部碎片。
解决方式:
一是利用DBCC INDEXDEFRAG整理索引碎片
二是利用DBCC DBREINDEX重建索引。
两者区别调用微软的原话如下:
DBCC INDEXDEFRAG 命令是联机操作,所以索引只有在该命令正在运行时才可用,而且可以在不丢失已完成工作的情况下中断该操作。这种方法的缺点是在重新组织数据方面没有聚集索引的除去/重新创建操作有效。
重新创建聚集索引将对数据进行重新组织,其结果是使数据页填满。填满程度可以使用 FILLFACTOR 选项进行配置。这种方法的缺点是索引在除去/重新创建周期内为脱机状态,并且操作属原子级。如果中断索引创建,则不会重新创建该索引。也就是说,要想获得好的效果,还是得用重建索引,所以决定重建索引。
以上可能部分文章借鉴了其他的网络文章,本文仅为学习使用,转载请注明出处
============ 欢迎各位老板打赏~ ===========

